이번 포스팅은 Transformer의 시초논문에 대해서 구조를 중심으로 리뷰하겠습니다.
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
transformer 구조에 대해 알아보기전, 우선 seq2seq와 attention에 대해서 간단히 읆어드리고 가습니다.
transformer 구조에 대해 알아보기전, seq2seq와 attention에 대해서 간단히 읆어드리고 가습니다.
Seq2Seq 모델과 Attention Mechanism 개념 정리

Seq2Seq 모델
- 구조: Seq2Seq 모델은 Encoder와 Decoder로 구성됩니다. Encoder는 입력된 데이터들을 고정된 크기의 Context Vector \( c \)로 변환하며, Decoder는 이 Context Vector를 기반으로 출력값을 생성합니다.
- 한계: 입력 데이터의 길이가 길 경우, 고정된 크기의 Context Vector에 모든 정보를 담기 어려워 성능 저하가 발생할 수 있습니다.

Attention Mechanism
- 기본 아이디어: 입력 데이터 중 당장 예측에 도움이 되는 값들만 골라서 활용하자는 개념입니다. 모든 정보를 하나의 벡터에 담을 필요가 없어지게 됩니다.
- 역사: Bahdanau et al. (2014)가 최초로 Attention 기법을 제안하며, 논문에서 이 기법을 "Alignment"라 칭했습니다.
Attention Mechanism의 구현
- Alignment Model (Score Function): 현재 Hidden State \( s_{t-1} \)와 각 입력의 Hidden State \( h_j \) 간의 유사도를 계산하여 Attention Score \( e_{t-1,j} \)를 구합니다.
\[ e_{t-1,j} = a(s_{t-1}, h_j) \]
Bahdanau et al. (2014)에서 제안한 모델:
\[ a(s_{t-1}, h_j) = v_a^T \tanh(W_a [s_{t-1}; h_j]) \]
여기서 \( v_a \)와 \( W_a \)는 학습 가능한 파라미터입니다. - Softmax: Attention Score를 Attention Weight \( \alpha_{t-1,j} \)로 변환합니다.
\[ \alpha_{t-1,j} = \frac{\exp(e_{t-1,j})}{\sum_{k=1}^{T_x} \exp(e_{t-1,k})} \] - Context Vector 계산: 계산된 Attention Weight와 Encoder의 Hidden State를 가중 평균하여 t 시점에서 사용할 Context Vector \( c_t \)를 계산합니다.
\[ c_t = \sum_{j=1}^{T_x} \alpha_{t-1,j} h_j \]
정리하면, Seq2Seq 모델은 고정된 Context Vector를 사용하여 입력 데이터를 압축한 후 Decoder에서 이를 기반으로 출력값을 생성하는 모델입니다.Attention Mechanism은 입력 데이터 중 필요한 부분에만 집중하여 예측 정확도를 높이는 기법입니다. Bahdanau et al. (2014)에 의해 제안되었으며, Context Vector를 매 시점마다 동적으로 계산하여 사용합니다.이 구조를 통해 모델은 입력 데이터의 길이에 관계없이 중요한 정보를 효과적으로 활용할 수 있게 되었습니다.
아래 그림에서 인코더와 디코더를 중심으로 설명하겠습니다.
트랜스포머의 주요 구성 요소

인코더 (Encoder)
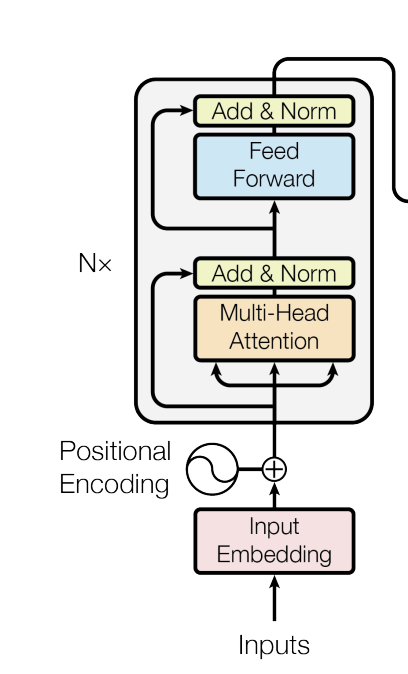
인코더는 입력 시퀀스를 받아 고차원 공간의 벡터로 변환합니다. 인코더는 N개의 동일한 레이어로 구성되며, 각 레이어는 다음과 같은 두 가지 주요 하위 레이어로 구성됩니다:
- 멀티-헤드 어텐션 (Multi-Head Attention):
- 여러 개의 어텐션 헤드를 사용하여 서로 다른 부분의 정보를 동시에 처리합니다. 어텐션 메커니즘은 입력 시퀀스의 각 단어가 시퀀스 내의 다른 단어들과 얼마나 관련이 있는지를 계산합니다.
- Feed Forward Network:
- 각 어텐션 출력에 대해 개별적으로 동일한 피드 포워드 네트워크를 적용합니다. 이 네트워크는 일반적인 완전 연결 신경망입니다.
각 하위 레이어 뒤에는 추가 및 정규화 (Add & Norm) 단계가 따라옵니다. 이는 입력에 대해 원래 입력과 출력의 합을 구하고 정규화를 수행합니다.
2. 디코더 (Decoder)

디코더는 인코더의 출력과 함께 주어진 입력을 사용하여 출력 시퀀스를 생성합니다. 디코더 역시 N개의 동일한 레이어로 구성되며, 각 레이어는 세 가지 주요 하위 레이어로 구성됩니다:
- Masked Multi-Head Attention:
- 디코더의 각 단계에서, 현재 위치의 단어와 그 이전 단어들만을 참조할 수 있도록 마스킹을 적용합니다. 이는 미래의 단어 정보를 차단하여 올바른 예측을 할 수 있게 합니다.
- Multi-Head Attention:
- 인코더에서 나온 출력과 디코더의 입력에 대해 어텐션을 적용합니다. 이는 입력 시퀀스와 현재 디코더 위치의 상호 관련성을 계산합니다.
- Feed Forward Network:
- 인코더와 동일한 방식으로 작동합니다.
각 하위 레이어 뒤에는 추가 및 정규화 (Add & Norm) 단계가 있습니다.
3. Positional Encoding

트랜스포머는 순차적인 데이터를 처리하지만, RNN과 달리 순서에 따라 입력을 처리하지 않기 때문에 위치 정보를 추가로 제공합니다. 이는 포지셔널 인코딩을 통해 이루어지며, 이 인코딩은 입력 임베딩과 더해져 위치 정보를 포함한 벡터를 만듭니다.
4. Output Probabilities

디코더의 최종 출력은 선형 계층과 소프트맥스 함수를 통해 확률 분포로 변환됩니다. 이 확률 분포는 각 단어가 다음에 나올 확률을 나타냅니다.
'Deeplearning' 카테고리의 다른 글
| [논문리뷰]AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ViT) (0) | 2024.07.24 |
|---|---|
| [논문리뷰]Neural Machine Translation by Jointly Learning to Align and Translate(Attention) (0) | 2024.07.19 |
| RNN에서 디코더와 인코더 (0) | 2024.07.13 |
| mAP(mean Average precision) (0) | 2024.05.23 |
| 모델 평가 지표 정리 (0) | 2024.05.23 |



